
Ich hatte ja bereits einen Artikeln über das Sichern seiner Funde verfasst. Dabei ging es aber um einzelne Webseiten oder kleine Listen von Webseiten. Wenn Du eine komplette Webpräsenz sichern willst, wären die in dem Artikel angesprochenen Methoden sehr aufwändig. Aber es gibt auch Programme die diese Arbeit erledigen.
Seit ca 2007 kannst Du z.B. mit HTTrack komplette Webseiten herunterladen. Das Programm steht für Windows, Linux und OSX zur Verfügung. Die meisten Alternativen arbeiten dagegen nur unter Windows. Falls Du HTTrack in Deiner virtuellen Linux Maschine installieren willst, benötigst Du die Pakete httrack und webhttrack. Ersteres ist eine reine Konsolenanwendung, mit dem zweiten kannst Du eine Weboberfläche zur Bedienung bekommen. Installieren kannst du die Programme im Linux-Terminal mit
sudo apt install httrack webhttrackMeine Anleitung bezieht sich auf webhttrack, aber die wesentlichen Informationen gelten genauso für die anderen Versionen von HTTrack oder alternative Programme. Wichtig ist es in den Einstellungen von HTTrack ein paar Änderungen zum Standard vorzunehmen! Die Hinweise dazu stehen in diesem Artikel.
Die Anwendung läuft auf dem Port 8080 in meiner VM. Gestartet werden konnte sie einfach aus dem Linux-Mint Menü
Nach dem Klick auf Weiter und ggf. vorgenommenen Spracheinstellungen musst Du ein Projekt anlegen:

Willst Du eine URL hinzufügen, musst Du nur dann auf den Button „URL hinzufügen…“ drücken, wenn Logindaten hinterlegt werden müssen. Wenn Du keine Logindaten mitgeben musst, wird empfohlen die URLs direkt ins weiße Feld unterhalb von „URL hinzufügen“ zu kopieren/schreiben.
Und jetzt kommen wir zum wichtigsten: Die Einstellungen! Denn diese müssen im HTTrack unbedingt vorgenommen werden. Nicht alle Voreinstellungen sind optimal.
Die erste Einstellung ist noch harmlos. Ob Du nun verbotene Verknüpfungen testen willst etc. ist Geschmackssache. Du kannst diese Einstellungen so lassen oder auch an den Eigenen Bedarf anpassen. Ich würde sie natürlich testen 🙂
Auch bei der Struktur, geht es hauptsächlich um persönliche Vorlieben, wie nun die Ablage gestaltet werden soll
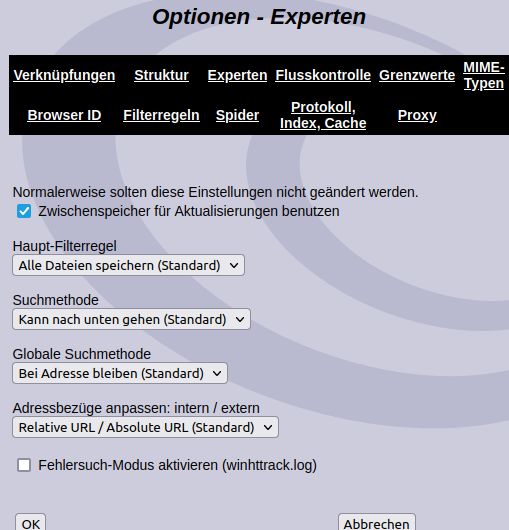
Hinter dem Link „Experten“ verbergen sich dagegen schon wichtigere Einstellungen. Wie zum Beispiel die Suchmethode. Soll nur nach „unten“ gesucht werden? Also die Frage ob nach bashinho.de/2023 nur die Dateien und Ordner unterhalb von 2023 durchsucht werden sollen wie bashinho.de/2023/12 oder nach oben zu bashinho.de gesucht werden soll oder eben beides. Das kann vor allem bei Anbietern relevant sein, bei denen mehrere Nutzer Unterverzeichnisse haben wie example.com/nutzer1, example.com/nutzer2 und man nur die Daten von Nutzer1 herunterladen möchte.
Genauso ist die „Globale Suchmethode“ interessant. Soll die genaue Adresse durchsucht werden, soll in der Domain geblieben werden, soll die Suche auf die TLD (.de) beschränkt werden oder überall im Netz gesucht werden. Je freier diese Einstellung gewählt wird umso größer wird die Datenmenge, die man herunterlädt. Wenn es keinen Grund dagegen gibt, würde ich hier maximal auf Domain erweitern.
Bei der Flusskontrolle geht es wiederum um Einstellungen die man auch so beibehalten kann.
Während die „Grenzwerte“ tatsächlich einen wesentlichen Einfluss haben, was heruntergeladen wird. Gerade eine hohe externe Tiefe kann zu völlig irrelevanten Sicherungen führen. Im schlimmsten Fall lädt man das ganze Internet herunter 😉 Aus meiner Sicht stellt sich eher die Frage ob man externe Seiten überhaupt mit sichern will. Wenn es keinen speziellen Grund gibt, würde ich hier immer 0 oder maximal 1 eintragen. Und auch bei der maximalen Tiefe kann man sich gerne beschränken. Wie vielen Links sollen innerhalb der Webseite gefolgt werden? 3? 5? 10? Das hängt natürlich von der Gestaltung der Webseite ab. An sich sollen ja im Webdesign alle Seiten innerhalb von 3 Klicks erreichbar sein, aber manchmal geht das nicht. Bei Bashinho.de sollten derzeit 3 Klicks tatsächlich ausreichend sein. Und auch Wartezeiten können sinnvoll sein, damit der Webserver nicht irgendwann dicht macht, weil zu schnell und zu oft hintereinander auf die Webseite zugegriffen wird.

Die Mime-Verknüpfungen sind aus meiner Sicht eher zu vernachlässigen
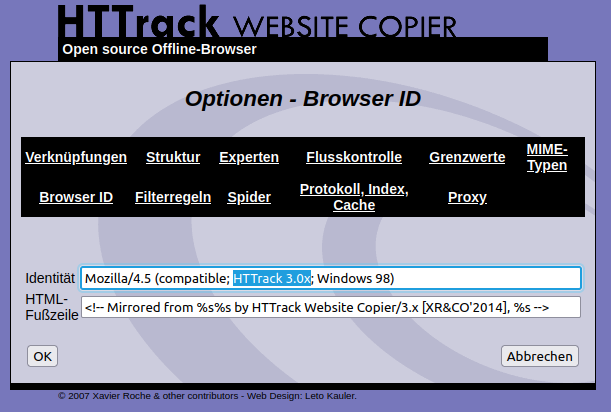
Die in den Optionen voreingestellte Browser ID, halte ich für fatal. Hier werden Webseitenbetreiber darauf hingewiesen, dass Du gerade ihre Webseite mit HTTrack herunterlädst. So etwas lässt sich serverseitig automatisiert verhindern. Hier sollte tatsächlich ein unverfänglicher aktueller User Agent String eingetragen werden, insbesondere da mache Webseiten die Ansicht bei zu alten Browsern verhindern. Deinen eigenen User Agent String kannst du bei Zendas sehen und in das Feld Identität kopieren.
Die HTML-Fußzeile betrifft nur einen Eintrag in die heruntergeladene Datei. Dadurch steht in den heruntergeladenen Dateien ein Kommentar, wie die Datei gesichert wurde.
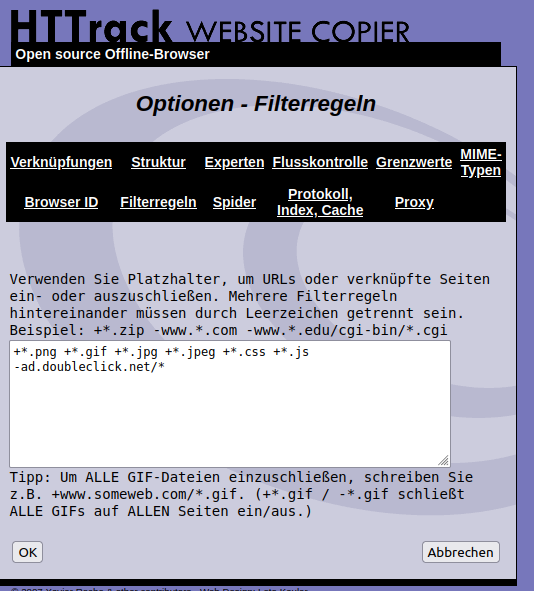
Die Filterregeln kannst Du so lassen, oder bei Bedarf anpassen
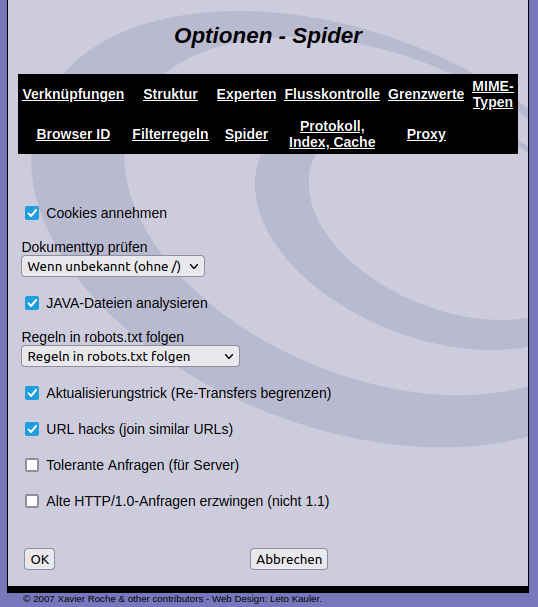
Beim Spider willst Du den Regeln der robots.txt natürlich nicht folgen ;). Vielleicht befinden sich ja wertvolle Hinweise in den „verbotenen“ Seiten.
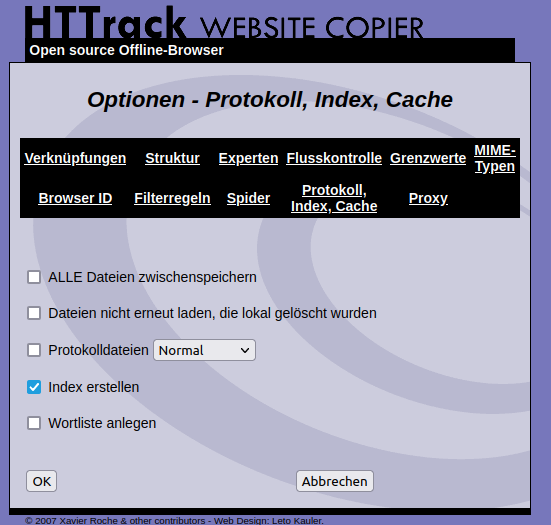
Bei den Protokolloptionen kannst Du wieder Deinen Vorlieben folgen
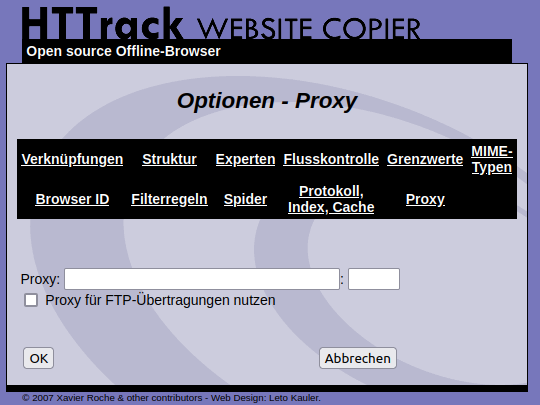
Du kannst natürlich einen Proxy eintragen, wenn Du vermeiden willst, dass die Zugriffe über die Eigene IP-Adresse registriert werden. Allerdings brauchst Du auch einen zuverlässigen Proxy. Ein Proxy ist ein Rechner über den der Datenverkehr geleitet wird. Im betrieblichen Umfeld, kann es sein, dass so ein Proxy eingetragen werden muss, weil über ihn der Internetzugang realisiert ist.
Wenn Du die Einstellungen dann gespeichert hast, kannst Du mit der Webseiten-Kopie starten
Aus meiner Erfahrung ist HTTrack ein recht zuverlässiger Webseitenkopierer, der aber hie und da auch Probleme mit einer Webseite hat. In dem Fall musst Du auf Alternativen wie Cyotek oder wget ausweichen. Die grundsätzlichen Hinweise die ich hier zu den Grenzwerten u.ä. geschrieben habe, gelten auch für Alternativen zu HTTrack.