
Mit regulären Ausdrücken kannst Du Textmuster beschreiben. Dazu ist es wichtig sich die Daten genau anzusehen um das Muster auch beschreiben zu können. Ich bin mir nicht sicher ob es leicht ist, mit diesem Textdokument reguläre Ausdrücke zu erlernen. Ich kann mir vorstellen dass es mit den Videos aus meiner Youtube-Playlist Datenaufbereitung in der Bash leichter zu erlernen ist und dieses Dokument besser als Nachschlagewerk genutzt werden sollte. Aber ich gebe mir Mühe reguläre Ausdrücke so einfach wie möglich zu erklären.
Nehmen wir an wir haben einen Datensatz der so aussieht
Nachname, Vorname Vorname
Wenn ich jetzt frage, wie Du den ersten Vornamen finden kannst, wie wirst Du ihn beschreiben? Das Muster für den ersten Vornamen ist eigentlich nicht schwer. Der erste Vorname steht nach einem Komma und einem Leerzeichen, also wäre das Muster Komma, Leer, Großbuchstabe, mehrere Kleinbuchstaben. Das überflüssige Komma Leer kann man ja hinterher rauslöschen.
Oder wenn ich frage, wie sieht eine IPv4 aus? Auch hier ist das Muster einfach, es kommen drei mal 1-3 Zahlen gefolgt von einem Punkt und dann kommen noch ein mal 1-3 Zahlen. Und das Muster ist so individuell, dass es für den regulären Ausdruck egal ist, dass die drei Zahlen höchstens den Wert 255 annehmen können. Aber auch das könnte man natürlich definieren – es würde den Ausdruck nur komplexer machen.
Oder, wie sieht eine IBAN aus? Am Beginn steht die Länderkennung, also zwei Buchstaben, danach folgen zwei Prüfziffern und danach kommen weitere Zahlen. Bei Deutschen Banken hat eine IBAN max. 22 Stellen, bei Banken im Ausland kann sie auch bis zu 34 Stellen lang werden.
Ein weiteres einfaches Beispiel wäre ein Domainname:
bashinho.de
Das Muster für diesen Domainnamen ist 8 Buchstaben, 1 Punkt, 2 Buchstaben. Willst Du dagegen Domainnamen allgemein beschreiben, müsstest Du Dir ansehen welche Zeichen in Domainnamen zulässig sind und wie lange die Top-Level Domain sein kann. Zulässige Zeichen sind Die Buchstaben von A bis Z, die Zahlen von 0 bis 9 und der Bindestrich. Beziehungsweise – so war das früher. Mittlerweile gibt es eine Latte weiterer Zeichen die zugelassen wurden. Die DENIC hat hier eine Liste mit den zusätzlichen 93 in .de Domains zugelassenen Zeichen bereitgestellt. Willst Du also wirklich alle Domains in einer Datenmenge finden, bleibt nichts anderes übrig als erst einmal zu recherchieren, wie die Domains aussehen können, damit Du sie später auch gut beschreiben kannst. Du kannst natürlich auch nach entsprechenden regulären Ausdrücken im Netz suchen und überprüfen ob sie deinen Anforderungen genügen.
Der Vorteil im OSINT ist, dass Du in der Regel nur „tote“ Daten auswertest und keine Nutzereingaben überprüfen musst. Daher reichen auch oft nicht so perfekte Ausdrücke für das richtige Ergebnis. Dazu habe ich weiter unten auch noch ein Beispiel.
Wichtig ist dass Du versteht einen Text abstrakt zu beschreiben. Diese Abstraktion ermöglicht es, das erkannte Muster einem Computer zu erklären.
Ich teile die Elemente von regulären Ausdrücken so ein:
1. Erlaubter oder verbotener Wert / Wertmenge
2. Wie oft darf dieser Wert / Wertmenge vorkommen
3. Zusatzinformationen / Standortinformationen wie Wortanfang, Zeilenanfang, Zeilenende
4. Entwertung, um ein Zeichen, das in regulären Ausdrücken eine Bedeutung hat, als Zeichen zu verwenden
Um Daten abstrakt zu beschreiben gibt es folgende Möglichkeiten:
Qualifier
| [ ] | Alle Zeichen zwischen der eckigen Klammer sind zugelassen. Achte darauf nicht aus Versehen Leerzeichen einzugeben. Beispiele: [A-Z] Alle Großbuchstaben von A-Z (ohne Umlaute u.ä.) [a-z] Alle Kleinbuchstaben von a-z (ohne Umlaute u.ä.) [0-9] Alle Zahlen von 0-9 [aZ8] Die Buchstaben kleines a, großes Z und die Zahl 8 sind zugelassen |
| [^] | Steht ein Dächle vor den Zeichen in der eckigen Klammer sind alle Zeichen darin verboten |
| . | Beliebiges Zeichen |
| \ | Entwertung eines Zeichens, das für reguläre Ausdrücke eine Bedeutung hat wie die eckige Klammer oder der Punkt. |
| ^ | Zeilenanfang (muss vor dem Ausdruck stehen) |
| $ | Zeilenende (der Ausdruck endet damit) |
| \< | Wortanfang (wurde erst später hinzugefügt, daher erhält das < seine Bedeutung erst durch die Entwertung) |
| \> | Wortende |
| [:alnum:] | Alphanumerische Zeichen. Beachte diese Wertmegen müssen nochmal in eckige Klammer im Ausdruck eingefügt werden: [[:alnum:]] |
| [:alpha:] | Buchstaben |
| [:blank:] | Leerzeichen und Tab |
| [:cntrl:] | Steuerungszeichen |
| [:digit:] | Zahlen |
| [:graph:] | Zeichen die sicht- und druckbar sind (Buchstaben, Zahlen, Leerzeichen usw.) |
| [lower:] | Kleinbuchstaben |
| [:upper:] | Großbuchstaben |
| [:xdigit:] | Hexadezimalzahlen |
| \\ | Entwertung des Entwertungszeichen |
| \n | Neue Zeile (LF) – Zeilenumbruch in Linux Dokumenten und neueren Mac Dokumenten |
| \r | Wagenrücklauf (CR) Zeilenumbruch in alten Mac Dokumenten. |
| \r\n | Windows nutzt zum Zeilenumbruch beide Zeichen (CRLF) |
| \t | Tabulator |
| \v | Vertikaler Tab |
| \f | Seitenumbruch |
Ein sehr schönes Beispiel um zu verdeutlichen wie reguläre Ausdrücke funktionieren, ist der Name Maier. Denn wie kann dieser Name geschrieben werden?
- Mayer
- Mayr
- Mair
- Meier
- Meyer
- Meyr
- Meijer
- Schundelmaier
Wenn Du Dir nun eine Tabelle zeichnest und die Buchstaben untereinander schreibst, kannst Du ein Muster erkennen
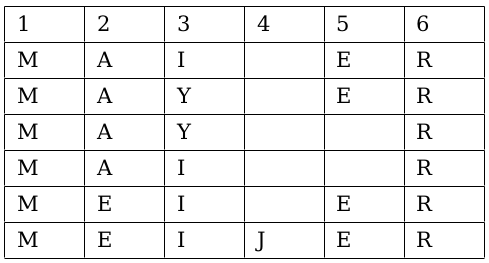
An der ersten Stelle kommt ein M.
An der zweiten Stelle kommen entweder ein A oder ein E.
An der dritten Stelle kommt entweder ein I oder ein Y.
An der vierten Stelle kommt ein J, dieses muss jedoch nicht vorhanden sein.
An der fünften Stelle kommt ein E, dieses muss jedoch nicht vorhanden sein.
An der sechsten Stelle kommt ein R.
Je nach dem ob Du nun erweiterte Ausdrücke nutzen willst, sieht das ganze dann wie folgt aus. Die Klammern, der Pipe und das Fragezeichen werden in der folgenden Tabelle erklärt:
(m|M)[ae](i|y)j{0,1}e{0,1}r
(m|M)[ae](i|y)j?e?r
Sollte es sich nur um einzelne Zeichen handeln macht es keinen Unterschied, ob Du nun [ae] oder (a|e) schreibst.
Quantifier
| regulär | erweitert | Anmerkung |
| ? | {0,1} | Der reguläre Ausdruck ? entspricht dem erweiterten Ausdruck 0,1 und bedeutet: Das davor stehende Zeichen kann – aber es muss nicht – an dieser Stelle vorkommen. |
| * | {0,} | Der reguläre Ausdruck * entspricht dem erweiterten Ausdruck 0, und bedeutet: Das davor stehende Zeichen muss zwar nicht vorkommen, es kann aber auch beliebig oft hintereinander vorkommen. .* (Punkt Stern) bedeutet, dass ein beliebiges Zeichen beliebig oft vorkommen darf – aber es muss nicht vorkommen. |
| + | {1,} | + oder seine alternative Schreibweise 1, bedeutet, dass das davor stehende Zeichen mindestens einmal vorkommen muss. |
| {2} | Die erweiterte Schreibweise ist natürlich flexibler. Die 2 ist hier nur ein Beispiel. Dieser Ausdruck bedeutet, dass das davor stehende Zeichen genau 2 mal aufeinander folgt. | |
| {2,6} | In diesem Beispiel muss das davor stehende Zeichne mindestens 2 aber höchstens 6 mal vorkommen. | |
| {,3} | Das davor stehende Zeichen darf maximal 3 mal vorkommen | |
| (|) | (|) | Das Konstrukt für Alternativen bzw. Oder. (1|2) bedeutet, dass an dieser Stelle 1 oder 2 stehen kann. Hierfür können natürlich auch komplexere Ausdrücke wie ([0-9]{3,}|[a-z]{5,10}) eingetragen werden. (Paul|Karl) Es dürfen nur die Namen oder besser gesagt Buchstabenfolgen Paul oder Karl vorkommen |
Ein paar Beispiele:
Ein regulärer Ausdruck für de-Domains könnte also wie folgt aussehen. Zugelassene Zeichen sind alle alphanumerischen Zeichen und das Minus. Die Länge der Domain darf zwischen 1 und 63 Zeichen haben. Dann folgt ein entwerteter Punkt, weil er sonst für ein beliebiges Zeichen stehen würde, gefolgt von de:
[[:alnum:]-]{1,63}\.deWichtig: Die Beschreibung für alphanumerische Zeichen [:alnum:] muss nochmal in die eckigen Klammen für Wertmenge eingefügt werden. Sollte ein Minus in der Wertemenge enthalten sein, muss dieses an letzter Stelle stehen, da das Minus in Wertemengen eigentlich von bis bedeutet.
Eine E-Mail-Adresse zu einer deutschen Domain könnte dann wie folgt aussehen. Alle alphanumerischen Zeichen zuzüglich diverser zugelassener Sonderzeichen. Diese kommen mindestens 1 bis 64 mal vor, dann folgt ein @ und danach der Ausdruck für Domains.
[[:alnum:]\.!#\$%&\'\*\+/=?\^_\`-]{|}-]{1,64}@[[:alnum:]-]{1,63}\.deTatsächlich kannst Du für OSINT das meist viel laxer machen. Es würde vermutlich folgender Ausdruck vollkommen ausreichen:
[[:alnum:]_\.-]{1,64}@[[:alnum:]-]{1,63}\.de
[[:print:]]{1,64}@[[:alnum:]-]{1,63}\.deMöglicherweise sogar auch dieser:
[A-Za-z0-9_\.-]+@[A-Za-z0-9-]+.deWarum kannst Du es bei einer OSINT-Auswertung laxer machen? Wenn Du den laxen Ausdruck in einen grep einbaut kannst Du mit >>grep -v<< die Auswahl umkehren und nochmal nach einem @-Zeichen suchen um zu sehen ob noch eine E-Mail-Adresse drin ist, die nicht gefunden wurde, und dann den Ausdruck eben anpassen. Ein Entwickler, der die Eingabe eines Formularfelds prüft, kann sich diesen Luxus nicht leisten.
grep -E '[[:alnum:]_\.-]{1,64}@[[:alnum:]-]{1,63}\.de'
grep -E '[[:alnum:]_\.-]{1,64}@[[:alnum:]-]{1,63}\.de' -v
grep -E '[[:alnum:]_\.-]{1,64}@[[:alnum:]-]{1,63}\.de' -v | grep '@'Außerdem kannst du false positives natürlich mit einem weiteren grep oder grep -v rauswerfen. Dies ist oft einfacher, als den Ausdruck nochmal umzuformulieren.
Die Suche nach einer IPv4 Adresse könnte dann wie folgt beschrieben werden. die Zahlen von [0-9] kommen 1-3 mal vor, dann folgt ein Punkt dann wieder die Zahl usw.
[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}Du kannst das auch noch zusammen fassen, weil sich der anfängliche Block ja 3x wiederholt. Also 1-3 Zahlen, gefolgt von einem Punkt. Für solche Zusammenfassungen werden runde Klammern verwendet und hinterher kommt der Quantifier
([0-9]{1,3}\.){3}[0-9]{1,3}Wenn Du zum Beispiel die privaten IP-Adressen 10., 192.168. und 172.16-31 aus seiner IP-Liste entfernen willst, kannst Du folgenden grep nutzen. Die regulären Ausdrücken bedeuten folgendes: Die IP-Adressen müssen am Zeilenanfang stehen. Die ersten beiden greps sind noch einfach. Bei der 172. er IP hast Du das Problem dass 16-19, 20-29 und 30-31 möglich sind, das bekommst Du über diesen Oder-Ausdruck also entweder eine 1 gefolgt von 6-9 oder eine 2 gefolgt von 0-9 oder eine 3 gefolgt von 0 oder 1 ganz gut hin.
grep -v '^10\.' | grep -v '^192\.168\.' | grep -Ev '^172\.(1[6-9]|2[0-9]|3[01]\.) Anderes Beispiel: In einer Datei habe ich als Trenner der Datensätze den Strichpunkt. Möchte ich überprüfen ob es Zeilen gibt bei denen der Trenner fehlt könnte ich z.B. folgende Suche initiieren
grep -v ';' Eigentlich sucht „grep“ alle Zeilen mit dem Strichpunkt, durch das −v werden nun aber alle Zeilen ausgegeben, die keinen Strichpunkt enthalten. Es ist viel einfacher eine Suche positiv zu formulieren und dann umzukehren, als eine Suche negativ zu formulieren.
Man kann „grep“s auch schachteln:
grep ';' | grep -v '^[^ ]' | grep '[a-zA-Z]+'
Der erste „grep“ würde alle Zeilen grepen die einen Strichpunkt enthalten und übergibt diese Zeilen an den zweiten „grep“, der besagt, dass die Zeilen nicht mit einem Leerzeichen beginnen dürfen und übergibt ihn dann an den dritten „grep“, der definiert, dass mindestens ein Buchstabe in der Zeile stehen muss.
Wichtig: Bei Daten, die von Nutzern eingegeben worden sind, darfst Du dich nie darauf verlassen, dass die Daten so sind, wie sie sein sollten. Ich habe z.B. schon erlebt, dass bei PLZ und Ort statt dem Ort nochmal die PLZ eingegeben wurde. Oder dass bei der PLZ auf einmal Länderkennungen vorgestellt waren. Es ist wichtig die Daten ordentlich zu untersuchen und seine regulären Ausdrücke umzukehren und den ausgeschlossenen Datenbestand nochmal zu durchsuchen. Zum Umkehren kennt grep den Parameter -v.
In meiner Youtube-Playlist Datenaufbereitung in der Bash habe ich das Thema auch als Video verfügbar gemacht. Die ersten vier Videos beschäftigen sich mit grep, aber auch später wie z.B. Video sieben und acht spielt grep eine Rolle. In den Videos habe ich den egrep verwendet, der das Selbe macht wie der grep -E – nur dass egrep nicht mehr verwendet werden soll. Daher habe ich in diesem Dokument grep -E den Vorzug gegeben.