
Egal ob du jetzt statt der Webseite eine HTTP Fehlermeldung wie 404 (die Seite konnte nicht gefunden werden) oder 503 (der Server ist nicht erreichbar) oder die Webseite aus einem anderen Grund nicht angezeigt werden kann. Diese Situation kann einem im Internet immer wieder passieren. In diesem Artikel zeige ich ein paar Möglichkeiten, wie man vielleicht doch den Inhalt zu Gesicht bekommen kann.
Google Cache
Google lädt für das Indizieren Webseiten herunter und speichert diese zwischen. Dankenswerterweise stellt Google diese Version einer Seite auch zur Verfügung. Leider hat Google die Möglichkeit, diese gespeicherten Webseiten anzusehen, aus der Oberfläche entfernt. Aufgrund der Meldung von Google ist zu erwarten dass folgender Workaround auch nicht mehr allzulange funktionieren wird.
Um die gecachte Version einer Webseite aufzurufen musst Du die gesuchte Webseite direkt in die URL eintragen. Beispiel:
https://webcache.googleusercontent.com/search?q=cache:https://bashinho.deNach dem Drücken der Return Taste wird man an die von Google zwischengespeicherte Version weitergeleitet:
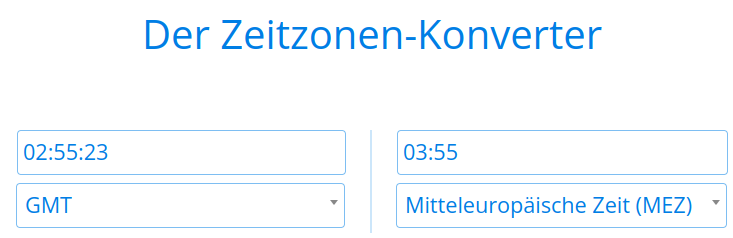
Oberhalb der Webseite wird von Google noch vermerkt, von wann diese Sicherung stammt. In diesem Fall vom 5. Dez. 2023 02:55:23 GMT. Die Zeitzonenangabe ist dabei wichtig. Sie ist in GMT nicht in der örtlichen Zeit. Man muss die Zeit also noch umrechnen (lassen), z.B. auf der Webseite Dateful
Wie alt die jeweilige Version ist, hängt davon ab wie häufig Google die Seite neu indiziert. Man hat hier keinen Einfluss, von wann die jeweilige Cache Version stammt. Meistens waren die Google Cache Versionen, die ich mir angesehen habe, wenige Stunden bis wenige Tage alt.
Wichtig: Bilder werden bei der Anzeige von der Original Webseite geholt. Das kann man einfach testen, indem man mittels einem Rechtsklick auf das Bild klickt und dann „Bild in neuem Tab öffnen“ auswählt. Die URL des Bildes ist die, der Original Seite:

Wenn man das verhindern möchte, muß man in der URL strip=0 auf strip=1 setzen. Dann erhält man eine reine Textanzeige. (In diesem Fall ist dies natürlich schon zu spät)

Archive.org
Das Internetarchive Archive.org existiert schon seit 1996 und lädt seit dem automatisiert Webseiten herunter und archiviert sie. Als Nutzer kann man aber auch das Speichern einer Seite veranlassen. Dadurch, dass der Dienst schon so lange im Netz verfügbar ist, hat er natürlich auch Unmengen an historischen Daten. Über die sogenannte Wayback Machine kann man sich diese alten Versionen einer Webseite ansehen. Gleich auf der Startseite erhält man ein Suchformular, in das man die gesuchte URL eintragen kann.

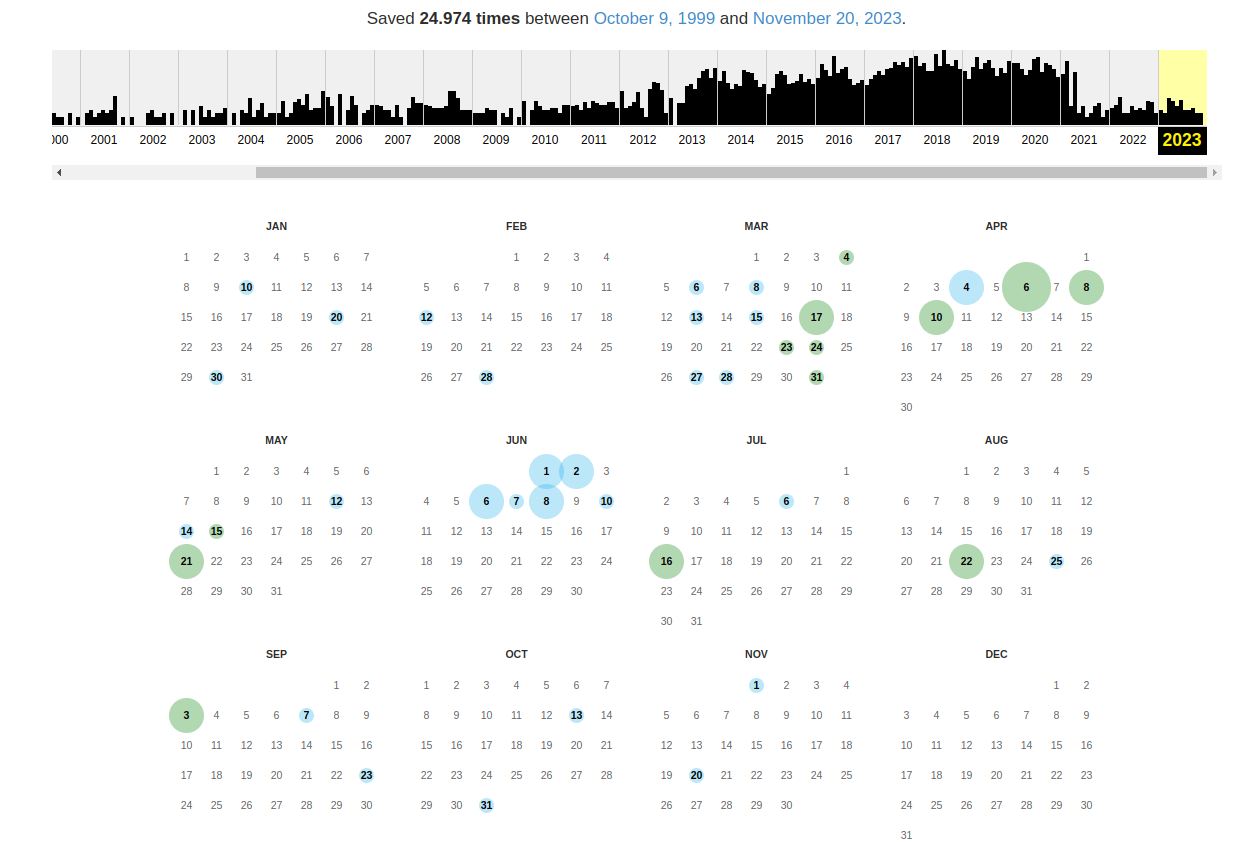
Leider ist nicht jede Webseite in jeder Version in der Wayback Machine gespeichert. Es gibt also keine Garantie, dass man das Gesuchte auch findet. Aber der Dienst ist schon sehr umfangreich. Ist eine Sicherung vorhanden erhält man einen Zeitstrahl und einen Kalender. Darüber kann man auswählen welche Sicherung man sich ansehen möchte:
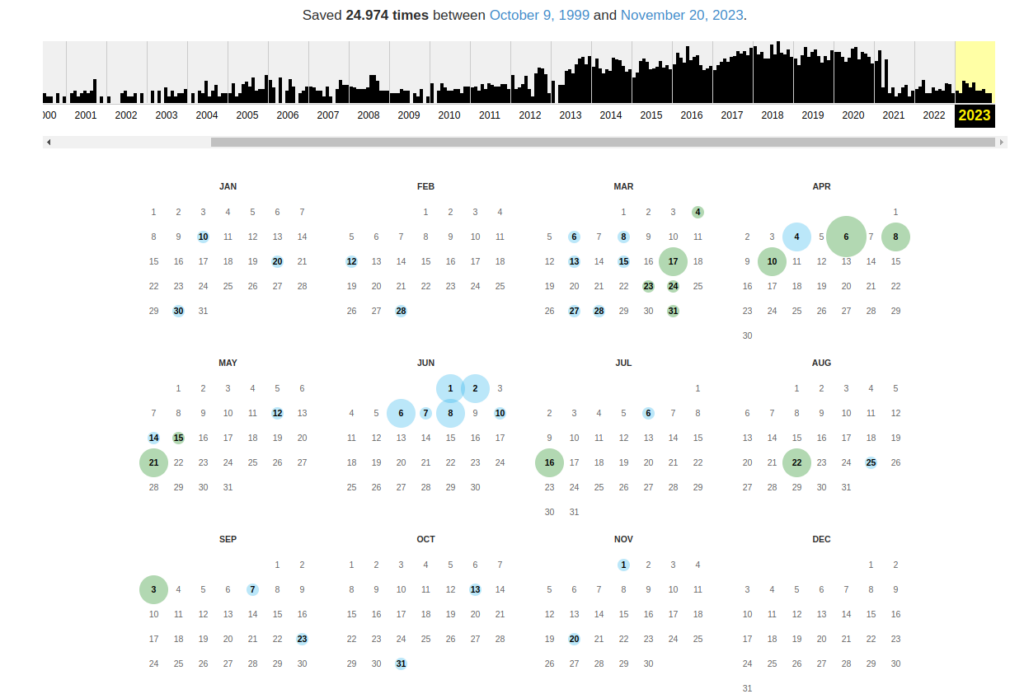
Wenn man mit der Maus über einen der farbigen Kreise fährt, bekommt man die Uhrzeiten der Sicherungen an diesem Tag angezeigt. (Leider war mir hier kein Screenshot möglich). Klickt man auf eine der Uhrzeiten wird man zur jeweiligen archivierten Webseite weitergeleitet. Je nach dem wie umfangreich die Sicherung von Archive.org war kann man auch auf Links klicken und weitere archivierte Seiten ansehen. Bilder werden in der archivierten Webseite mitgespeichert, sie werden also beim Ansehen nicht von der original Webseite geholt.
Will man selber eine Webseite nach Archive.org speichern, muß man folgendes Formular (unten rechts) auf dieser Webseite befüllen.
Danach muß man nochmal eine Rückfrage beantworten (ein Einloggen ist nicht erforderlich).
Nach dem Klick auf „Save Page“ wird die Webseite nach Archive.org gespeichert.
Archive.today
Seit 2012 gibt es mit Archive.today ein weiteres Webarchiv, welches noch unter weiteren URLs wie archive.ph, archive.is uvm. aufgerufen werden kann. Manchmal funktioniert die eine URL, manchmal eine andere.
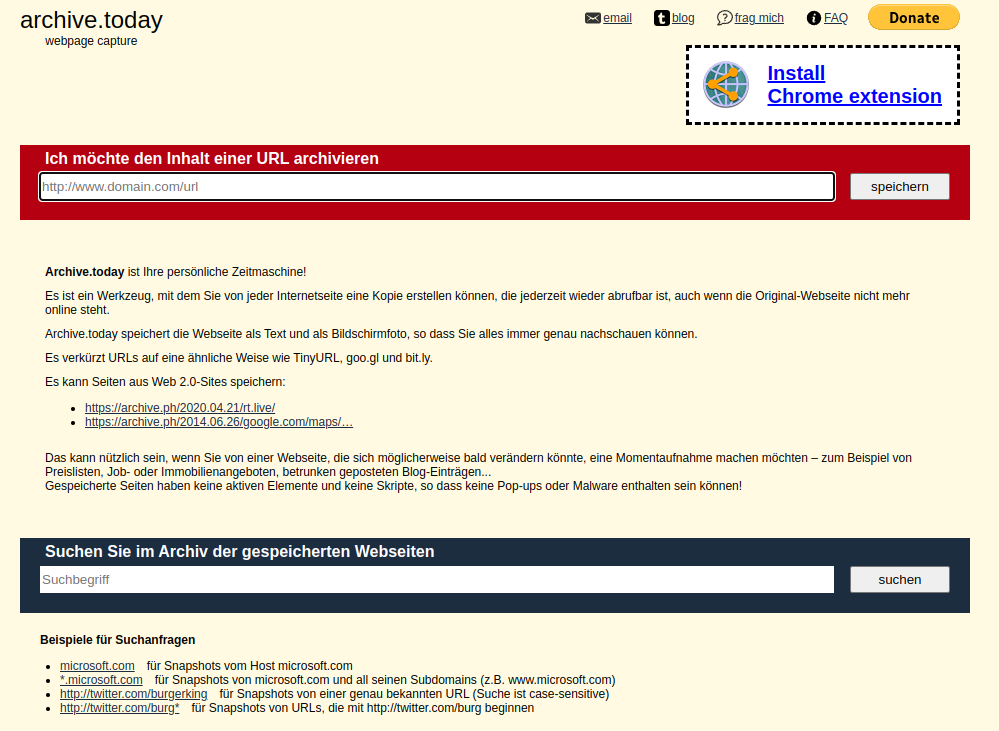
Auf der Startseite wird man gleich gefragt, ob man nun eine URL archivieren oder eine gespeicherte Webseite aufrufen will. Wenn es mehrere gespeicherte Varianten einer Webseite gibt, werden einem die einzelnen Sicherungen von alt nach neu angezeigt.
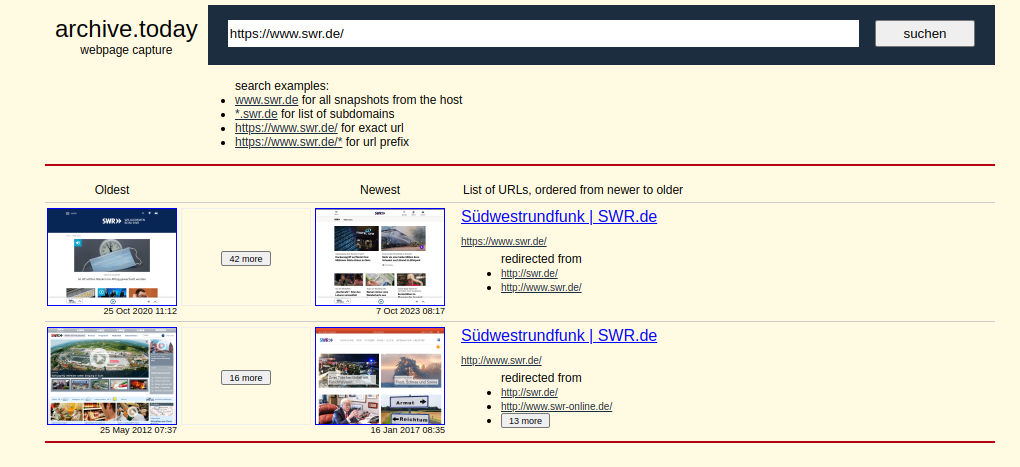
Jetzt muss man nur noch die gewünschte Version anklicken um Zugriff zu erhalten. Auch hier werden Bilder in der archivierten Webseite mitgespeichert, sie werden also beim Ansehen nicht von der original Webseite geholt.
Addons
Wie immer gibt es kleine Helferlein, die man sich in den Browser installieren kann und mit deren Hilfe man eine Webseite sehr einfach in seiner archivierten Variante aufrufen kann.
Webarchives (Firefox, Chrome)
Wayback Machine (Firefox, Chrome)
Fazit
Google Cache und Webarchive sind eine tolle Möglichkeit, sich ältere Stände einer Webseite anzusehen. Das ist nicht nur nützlich wenn es zu den Eingangs genannten Fehlermeldungen kommt. Ein Beispiel aus meiner Vergangenheit: Ich kann leider nicht zu sehr ins Detail gehen, aber eine Firma hat eine Pressemeldung herausgegeben in der sie etwas behauptet hat. Ich hab mir dann eine wenige Tage ältere Version ihrer Webseite im Google Cache angesehen und stellte fest: die Pressemeldung war einfach gelogen (Auf der Seite im Google Cache stand genau das, was sie in der Pressemeldung bestritten). Sie haben kurz vor der Pressemeldung einfach ihre Homepage geändert (und witzigerweise nur in der deutschen Sprachversion – in der englischen stand das, was sie bestritten haben, immer noch drin)
Webarchive bieten neben der Möglichkeit alte Webseiten anzusehen, auch die Option eine Webseite zu speichern. Das kann immer dann nützlich sein, wenn man jemand die eigene Sicherung anzweifelt. So kann man auf die Sicherung durch Dritte verweisen, auf die man selbst ja keinen Einfluss hatte, außer dem Umstand, dass man sie ausgelöst hat.