
Manchmal hat man viele Webseiten, die man untersuchen will. Anhand des Beispiels E-Mail-Adresse will ich zeigen, wie man mit Linux Board Mitteln sehr einfach diese gesuchten Daten extrahieren kann.
Die Basis dieses Ansatzes ist das Programm curl mit dem man sich einfach auf Webserver verbinden und Daten abrufen kann. Will man z.B. die Webseite Bashinho.de abrufen gibt man im Terminal einfach folgendes ein:
curl "https://bashinho.de"Es empfiehlt sich tatsächlich die URL in Anführungszeichen zu setzen. Die Webseite wird in der Regel nicht lauffähig sein, weil eingebettete css-Stylesheets, Javascripts etc. nicht mit heruntergeladen werden. Außerdem wird der HTML Quellcode der Webseite zwar ausgegeben aber nicht gespeichert.
Jetzt möchten manche Webseiten derartige Aufrufe nicht und versuchen diese zu verhindern. In der Regel lässt sich das Problem lösen, indem man eine Browserkennung, den sogenannten User Agent String mitgibt.
curl "https://bashinho.de" --user-agent "Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0"Da der User-Agent-String Leerzeichen enthält, ist die Mitgabe der einschließenden Hochkommata unerlässlich. Deinen User-Agent kannst Du z.B. bei Zendas herausfinden.
Wenn man curl jetzt auf eine Liste mit URLs loslassen möchte, findet man in der manpage (man curl) leider keine Hilfe. Aber der Trick, den ich schon in meinem Artikel über „Einfache Datenauswertung für OSINT“ gezeigt habe, funktioniert auch mit curl.
Zuerst muss man seinen curl Befehl noch etwas vorbereiten, da das Anführungszeichen für den awk eine Bedeutung hat. Die Anführungszeichen müssen maskiert werden.
curl \""$1"\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\"Anstelle der URL gebe ich „$1“ ein. Das sagt dem awk, den ich später verwende, dass er die erste Spalte in der durch Leerzeichen getrennten Liste betrachten soll. In dieser Liste gibt es natürlich nur eine Spalte, aber bei anderen Listen könnte das natürlich interessant sein.
Mit cat kann man sich die Liste der URLs ausgeben lassen.
cat liste.txt 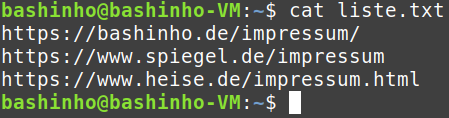
Diese Liste kann man nun awk übergeben, der dann den curl Befehl ausdrucken soll und dabei die URL jeweils durch die in der Liste angegebene URL ersetzt
cat liste.txt | awk '{print "curl \"" $1 "\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\""}'
Wenn man nun diese Ausgabe an die Bash übergibt, werden die Befehle ausgeführt und die Webseiten ausgegeben (HTML-Quelltext, sie werden nicht gespeichert sondern nur angezeigt.)
cat liste.txt | awk '{print "curl \"" $1 "\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\""}' | bashUm jetzt noch die E-Mail-Adressen zu extrahieren nimmt man den grep -E oder solange er noch geht auch den egrep. Es ist der selbe Befehl, nur die Schreibweise ist unterschiedlich.
Wenn man weiß wie reguläre und erweiterte Ausdrücke geschrieben werden kann man sich schnell einen schreiben. Alternativ kann man auch eine beliebige KI fragen und hoffen dass man einen guten Ausdruck bekommt:
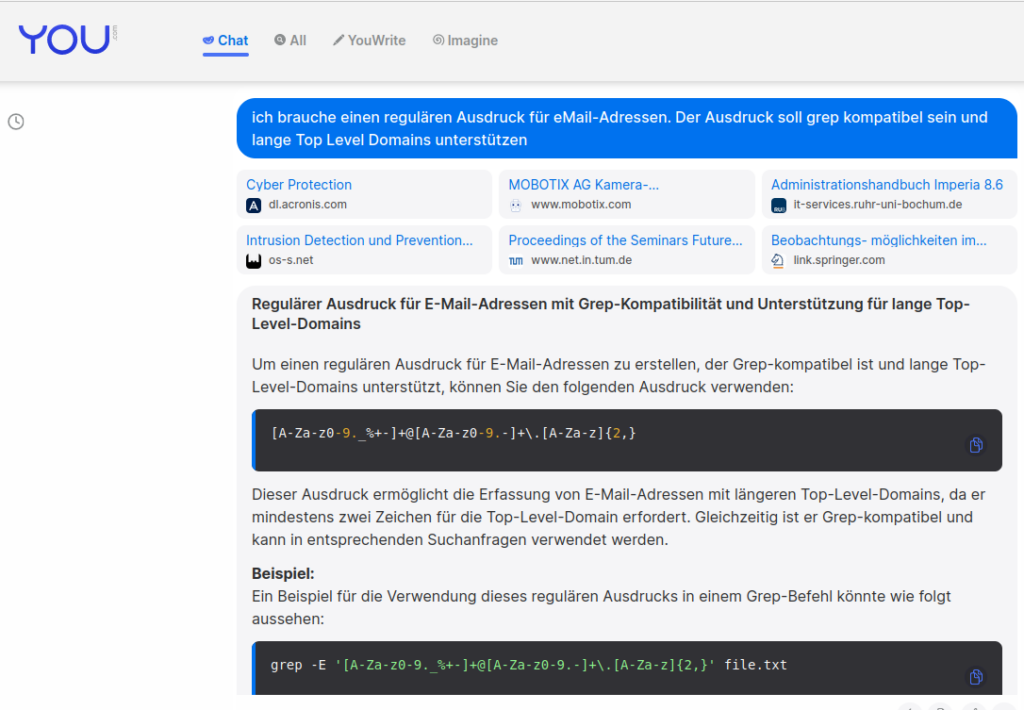
Den bisherigen Befehl leitet man nun mit dem Pipe an den grep weiter
cat liste.txt | awk '{print "curl \"" $1 "\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\""}' | bash | grep -E '[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}' -o Das -o sorgt dafür, dass die E-Mail-Adressen ausgeschnitten werden. Möchte man die Liste gleich speichern, leitet man das Ergebnis noch in eine Textdatei um (das geht mit dem größer als Zeichen: > dateiname)
cat liste.txt | awk '{print "curl \"" $1 "\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\""}' | bash | grep -E '[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}' -o > emails.txtStatt nach einer E-Mailadresse kannst Du natürlich nach allem möglichen anderen suchen, solange es sich mit regulären Ausdrücken beschreiben lässt. Beispiele könnten z.B. Telefonnummern oder Bitcoin-Adressen sein.
Falls Du viele Seiten ein und der selben Domain untersuchen willst, solltest Du bedenken, dass viele Webseitenbetreiber solch aggressives Scraping unterbinden. Für so einen Fall muss der Befehl ausgebremst werden und das geht mit dem sleep Kommando. Dieses wird im awk nach dem curl eingefügt. sleep 1 bedeutet, dass eine Sekunde gewartet werden soll. Den Wert kannst Du natürlich beliebig hochsetzen. Aber eine Sekunde sollte für die meisten Fälle ausreichend sein. Wenn Du nun 60 URLs überprüfen willst, verlängert sich die Dauer um eine Minute. Das ist aus meiner Sicht ein akzeptabler Kompromiss.
cat liste.txt | awk '{print "curl \"" $1 "\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\";sleep 1"}' | bash | grep -E '[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}' -o > emails.txtMöchtest Du vor der Mailadresse noch die URL haben, in der die Mailadresse gefunden wurde, ist grep -o keine gute Option. Da grep -o den Suchstring ausschneidet. In einer heruntergeladenen Datei kommen aber E-Mail-Adressen möglicherweise mehrfach vor. D.h. es ist fast unmöglich mit dem grep den Dateinamen mitauszugeben. Aber der AWK kann auch mit regulären Ausdrücken suchen. Folgende Alternative sollte also helfen:
cat liste.txt | awk '{print "echo -n URL"$1" \" \";curl \"" $1 "\" --user-agent \"Mozilla/5.0 (X11; Linux x86_64; rv:120.0) Gecko/20100101 Firefox/120.0\"; sleep 1"}' | bash | sed 's/>/>\n/g' | awk 'BEGIN{regex="[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,}"}$1~/URLh[^ ]+/{url=$1} {if(match($0,regex)){print substr(url,4)" " substr($0,RSTART,RLENGTH)}}' | sed 's/ //g' | sort | uniq > url_emails.txtFalls das alles noch Neuland für Dich ist, kannst du gerne meine Videoreihe „Datenaufbereitung in der BASH“ ansehen. Dort erkläre ich Schritt für Schritt wie diese Befehle funktionieren und wie man sie kombiniert.
Hinweis: Natürlich können auf diesem Weg nur E-Mail-Adressen gefunden werden, die auch so als Text im HTML-Dokument stehen. Werden die E-Mail-Adressen als Bilder eingebunden oder anders obfuskiert, werden sie nicht gefunden.
Und falls das alles für Dich zu kryptisch ist. Du kannst das alles einfach kopieren. Du benötigst ein Dokument in dem URLS stehen, die mit http oder https bestehen. In jeder Zeile steht eine URL. Dieses Dokument soll liste.txt heißen. Du öffnest ein Terminal in dem Ordner in dem das Dokument liegt und kopierst meinen Befehl in das Terminal. Falls du einen anderen Regulären Ausdruck benötigst musst du den Bereich zwischen den Anführungszeichen von regex=““ austauschen. Und falls dir noch das Linux mit dem Terminal fehlt. Hier ist eine Installationsanleitung von mir oder du nutzt meine Youtube Playlist zu Virtuellen Maschinen.
Für Eingeweihte möchte ich kurz erklären was ich nun geändert habe:
Die awk-Funktion match hat beim Erstellen der Bash-Zeile nur ein Ergebnis in einer Zeile getroffen. Daher habe ich mit sed einen Zeilenumbruch erzeugt, wenn ein > erscheint. Jeder HTML-Tag endet mit einem >. D.h. ich habe dafür gesorgt, dass nach jedem Tag ein Zeilenumbruch entsteht. Dadurch ist sichergestellt, dass jede E-Mail-Adresse in einer einzelnen Zeile steht (Bei der Annahme, dass alle E-Mail-Adressen auch mit HTML-Tags verlinkt wurden und nicht in einer einfachen kommaseparierten Liste stehen).
Im BEGIN des awk definiere ich jetzt den regulären Ausdruck für die Email-Adressen.
$1~/URLh[^ ]+/{url=$1} prüft ob eine Zeile das Schlüsselwort URL und das h von http enthält und danach noch mehrfach keine Leerzeichen kommen. Das Schlüsselwort URL hatte ich im ersten awk mit einem echo eingefügt gehabt. Die Zeilen sollten daher immer so aussehen URLhttps://… $1 wird dann in die Variable url geschrieben.
{if(match($0,regex)){print substr(url,4)“ “ substr($0,RSTART,RLENGTH)}}‘ in jeder Zeile wird nun geprüft ob der reguläre Ausdruck trifft, und wenn ja, wird er und die URL ausgeschnitten und ausgegeben. RSTART und RLENGTH sind automatisch erzeugte Variablen, die besagen wann der match startet und wie lange der match ist. Bei der URL werden die Buchstaben URL entfernt, die ich zuvor als Erkennungszeichen hinzugefügt hatte.
sed ’s/ //g‘ warum auch immer. in manchen Zeilen hat sich diese Zeichenkette ins Ergebnis geschmuggelt. Jetzt wird sie halt gesucht und durch nichts ersetzt.
Und mit sort | uniq werden einfach doppelte Einträge entfernt. Wenn eine E-Mail-Adresse auf unterschiedlichen Seiten vorkommt, wird sie mehrfach in der Liste sein. Aber wenn sie auf der selben Seite mehrfach vorkommt wird sie entfernt.
Fazit
Es ist immer wieder erstaunlich wie viel Programme und Github Projekte man findet, die einem die ein oder andere Möglichkeit für OSINT geben. Oft kann man das selbe aber auch mit der Bash erledigen, wenn man ein paar Befehle kennt.